W świecie sztucznej inteligencji panuje nieustanny wyścig o większą moc i lepsze wyniki. Często jednak zapomina się o drugiej stronie medalu: astronomicznych kosztach operacyjnych i ogromnym zużyciu energii. Na tym tle pojawia się MiniMax M2.5 – model, który celowo redefiniuje priorytety. Jego twórcy, jak wskazuje Caleb Writes Code, postawili na inteligentną równowagę między wysoką wydajnością a przystępnością cenową, co może zmienić reguły gry dla developerów i firm.
Innowacja w rdzeniu: mechanizm rzadkiej aktywacji
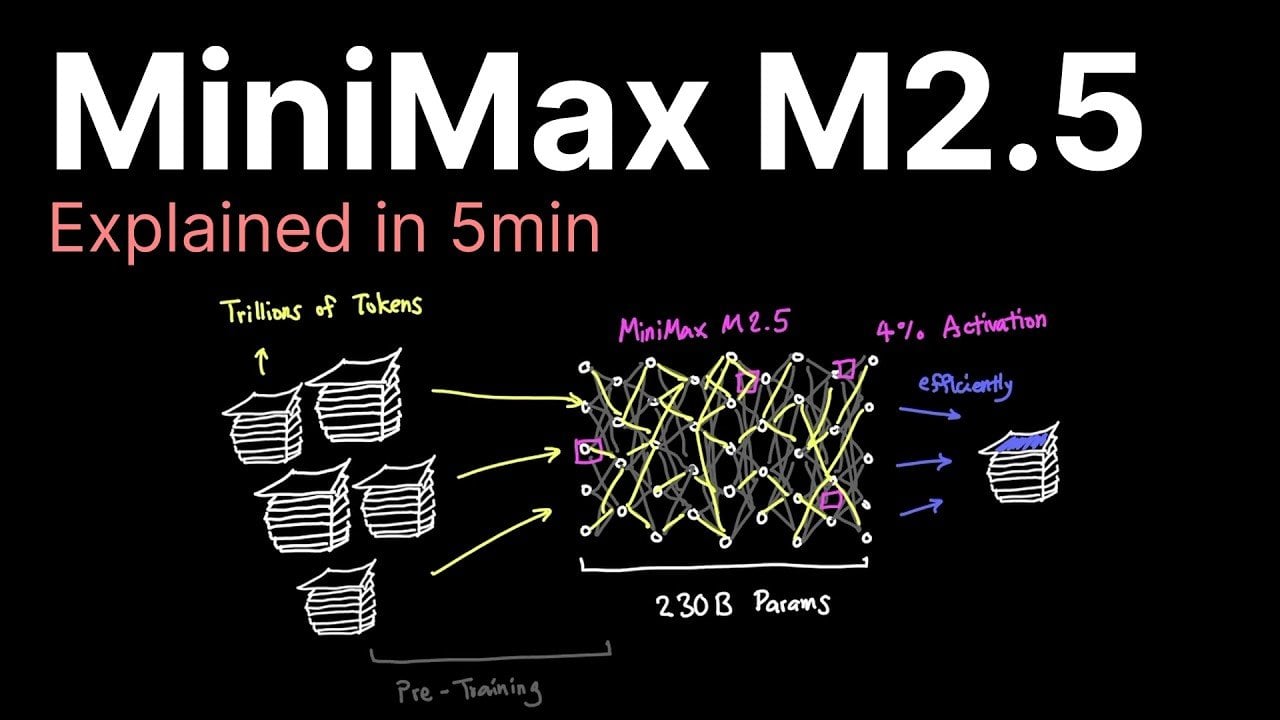
Sercem nowego modelu jest rewolucyjne podejście do architektury, znane jako rzadka aktywacja (sparse activation). Tradycyjne, gęste modele językowe angażują do przetworzenia każdego tokenu praktycznie wszystkie swoje parametry. MiniMax M2.5 działa inaczej. Z ogromnej puli 230 miliardów parametrów, dla pojedynczej jednostki tekstu aktywuje zaledwie 10 miliardów, co stanowi około 4% całości.
Wydajność bez kompromisów
Pomimo tak radykalnej oszczędności, model nie traci na jakości. Na benchmarku Sweetbench osiąga około 80% skuteczności w porównaniu do czołowych rozwiązań, takich jak Anthropic Opus 4.6. Oznacza to, że dla wielu praktycznych zastosowań różnica w jakości odpowiedzi będzie ledwo zauważalna, podczas różnica w rachunkach za infrastrukturę – kolosalna.
Korzyści płynące z selektywności
Skupienie się tylko na niezbędnych parametrach przynosi wymierne efekty. Przede wszystkim drastycznie spada zapotrzebowanie na energię, co ma pozytywny wpływ na środowisko i portfel. Po drugie, proces generowania tokenów przyspiesza, umożliwiając szybsze działanie aplikacji. Wreszcie, całość przekłada się na nieosiągalną dotąd relację kosztu do wydajności.
Przełomowa efektywność kosztowa
Gdzie MiniMax M2.5 naprawdę błyszczy, to w ekonomice swojego działania. Jego struktura cenowa jest zaprojektowana tak, aby zaawansowana AI była dostępna nie tylko dla gigantów technologicznych, ale także dla mniejszych zespołów i startupów.
Liczby, które zmieniają perspektywę
Koszt generowania tokenów wyjściowych przez M2.5 szacuje się na zaledwie 3% kwoty, jaką trzeba zapłacić za korzystanie z Anthropic Opus 4.6. Szybkość pracy również imponuje – model jest w stanie przetwarzać około 100 tokenów na sekundę, czyli niemal dwukrotnie szybciej niż część konkurencji. Dla organizacji planujących ciągłe użytkowanie przy prędkości 50 tokenów/sekundę, roczny koszt operacyjny może zamknąć się w kwocie około 1892 dolarów.
Przejrzysta i atrakcyjna cennik
MiniMax proponuje prosty model rozliczeniowy. Cena za milion tokenów wejściowych wynosi 30 dolarów. Jeszcze bardziej przykuwa uwagę koszt tokenów wyjściowych – tylko 1,20 dolara za milion. Taka polityka cenowa czyni eksperymentowanie i wdrażanie rozwiązań opartych na AI znacznie mniej ryzykownym finansowo.
Output token generation costs just 3% of Anthropic Opus 4.6.
Szybki rozwój i wpływ na rynek AI
Serię MiniMax charakteryzuje niezwykłe tempo innowacji. Wersja M2.5 ujrzała światło dzienne zaledwie 50 dni po premierze modelu M2.1. Tak szybki cykl rozwojowy pokazuje, że twórcy są nie tylko technologicznie sprawni, ale też świetnie wsłuchują się w potrzeby użytkowników i dynamicznie reagują na trendy rynkowe.
Upowszechnienie się tak wydajnych kosztowo modeli jak M2.5 może głęboko przeobrazić krajobraz sztucznej inteligencji. Zmniejsza się uzależnienie od drogiego, specjalistycznego sprzętu, takiego jak klastry GPU. To z kolei prowokuje ważne pytania o przyszłość infrastruktury IT. Czy era masowego przewymiarowania (overprovisioning) mocy obliczeniowej na potrzeby AI dobiega końca? A może, zgodnie z paradoksem Jevonsa, niższe koszty jednostkowe po prostu przyspieszą i poszerzą adopcję, finalnie zwiększając globalne zapotrzebowanie na moc?
Przyszłość: agenci zawsze włączeni i szerszy dostęp
MiniMax M2.5 to nie tylko narzędzie na dziś, ale także krok w kierunku konkretnej wizji przyszłości. Jego ekonomika umożliwia realizację koncepcji „zawsze włączonych agentów” – autonomicznych systemów AI działających non-stop przy minimalnych kosztach utrzymania. Otwiera to drzwi do nowej klasy aplikacji, które dotąd były nieopłacalne.
Potencjał otwartości i lokalnych wdrożeń
Choć obecne wymagania sprzętowe (około 400 GB pamięci VRAM) stawiają barierę dla wdrożeń mobilnych, dalsze optymalizacje mogą to zmienić. Kluczowym krokiem dla społeczności byłoby otwarcie wag modelu (open-sourcing). Pozwoliłoby to developerom na uruchomienie M2.5 lokalnie, z niższą precyzją, jeszcze bardziej obniżając koszty i zwiększając kontrolę nad danymi.
Ostatecznie, MiniMax M2.5 symbolizuje szerszy trend w branży: dążenie do demokratyzacji sztucznej inteligencji. Poprzez łączenie innowacyjnej technologii z przystępnością cenową model ten pokazuje, że zaawansowana AI może stać się narzędziem powszechnym, służącym zarówno wielkim korporacjom, jak i małym firmom czy indywidualnym twórcom. To nie wyścig o rekord za wszelką cenę, a inteligentna ewolucja w kierunku praktycznej użyteczności i zrównoważonego rozwoju.

iOS 27: Siri staje się samodzielną aplikacją chatbot

Nothing wkracza na rynek smart glasses z AI. Co wiemy?
Jak zautomatyzować 80% pracy dzięki Claude AI? Praktyczny poradnik
Szef największego szpitala w USA chce zastąpić radiologów AI

AI w biotech: Kto naprawdę wygrywa wyścig technologiczny?

Gemma 4 od Google: otwarty, multimodalny model AI

Google Stitch: Jak AI zmienia prototypowanie i design interfejsów

Automatyzuj zadania na Macu z Claude Desktop i Computer Use

Jak ChatGPT tworzy złożone formuły Excel w kilka sekund

Ray-Ban Meta 123.1: Lepsze AI, nowe języki i funkcje na stok
6 nowych narzędzi AI w Microsoft 365 dla nauczycieli
