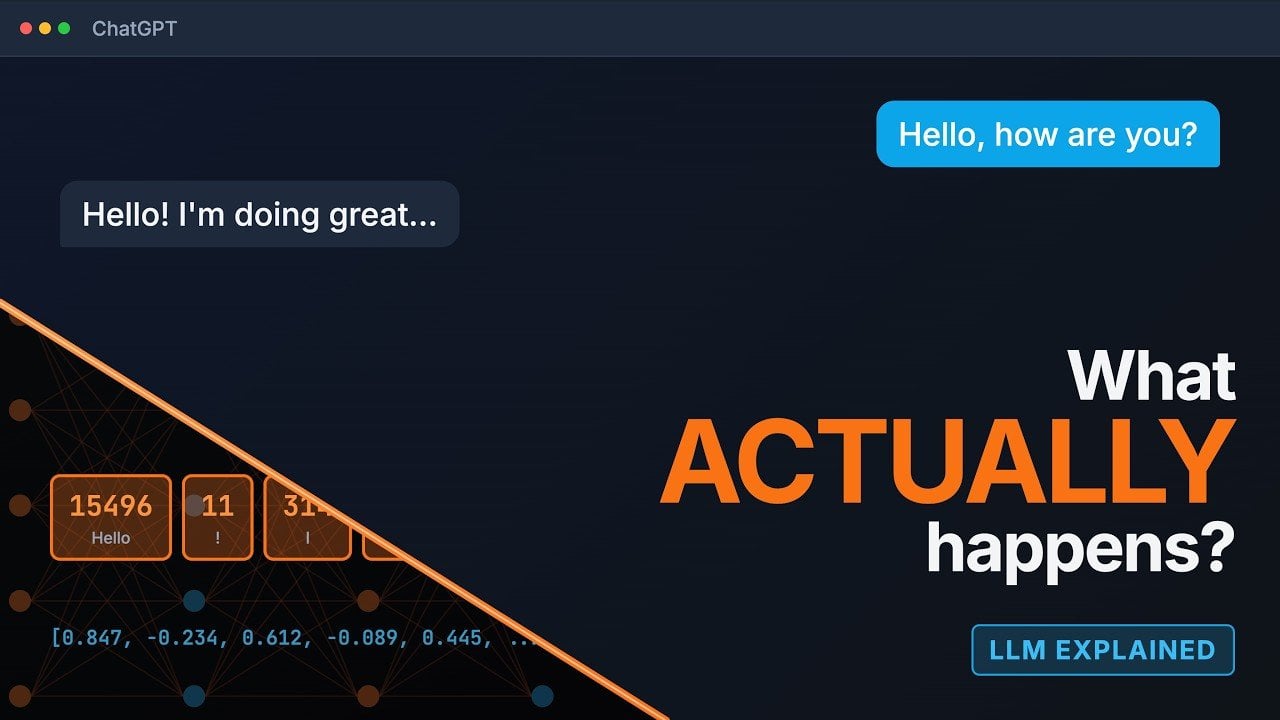
Od magicznej skrzynki do zrozumiałego mechanizmu
Duże modele językowe, takie jak ChatGPT, Claude czy Gemini, potrafią prowadzić rozmowę w sposób, który często wydaje się zaskakująco naturalny. To wrażenie rodzi pytanie: co właściwie dzieje się w środku, gdy AI generuje tekst? Proces ten, choć technicznie złożony, można prześledzić krok po kroku. Zespół Learn That Stack postanowił go rozpracować, pokazując, że za pozornie prostą odpowiedzią stoi seria precyzyjnych etapów łączących kontekst, spójność i odrobinę obliczonej przypadkowości.
Zrozumienie tych mechanizmów pozwala przestać postrzegać AI jako czarną skrzynkę, a zacząć traktować ją jako narzędzie, z którego można świadomie korzystać. Poniżej przedstawiamy pięć kluczowych faz, przez które przechodzi każdy prompt, zanim na ekranie pojawi się gotowa odpowiedź.
1. Tokenizacja: Rozbijanie języka na kawałki
Wszystko zaczyna się od podziału Twojego zapytania na mniejsze, zarządzalne jednostki zwane tokenami. Tokenem może być całe słowo, jego fragment (np. przedrostek) lub pojedynczy znak – wszystko zależy od konkretnego modelu. Każdy z tych kawałków otrzymuje unikalny numer ID, który komputer może łatwo przetwarzać.
Ma to bezpośredni wpływ na praktyczne użycie modeli. Limity podawane w interfejsach API (np. „max 4096 tokenów”) odnoszą się właśnie do tych jednostek, a nie do pełnych słów. Długie lub złożone wyrazy, takie jak „niezrozumiałe”, mogą zostać podzielone na kilka tokenów, szybko zużywając dostępny limit. Świadomość tego procesu pomaga formułować prompts w sposób bardziej efektywny i oszczędny.
2. Embeddingi: Gdzie słowa zyskują znaczenie
Gdy tokeny są już przygotowane, przechodzą transformację w procesie zwanym embeddingiem. Każdy numeryczny ID zamieniany jest na wektor – punkt w wielowymiarowej przestrzeni, który reprezentuje jego „znaczenie”. W tej matematycznej przestrzeni słowa o podobnym sensie znajdują się blisko siebie. Wektory dla „kota” i „kocięcia” będą sąsiadować, podobnie jak te dla „biegać” i „sprintować”.
To mapowanie pozwala modelowi uchwycić subtelne związki semantyczne i kontekstowe. Dzięki temu AI rozumie, że „bank” w zdaniu o rzece oznacza coś innego niż „bank” w zdaniu o finansach. Ta zdolność do operowania znaczeniem, a nie tylko suchymi słowami, jest fundamentem generowania treści, które są merytorycznie trafne i bogate kontekstowo.
3. Mechanizm Transformer: Architektura, która rozumie kontekst
Sercem nowoczesnych LLM jest architektura transformer. Jej najpotężniejszym elementem jest mechanizm uwagi (attention), który analizuje relacje między wszystkimi tokenami w tekście. Działa to w wielu warstwach, z których każda pogłębia rozumienie kontekstu.
Mechanizm uwagi pozwala modelowi „skupić się” na najbardziej istotnych fragmentach wejścia podczas generowania odpowiedzi. Gdy zapytasz o stolicę Francji, model przyłoży większą wagę do tokenów związanych z geografią i nazwami państw, pomijając mniej istotne informacje z kontekstu. To właśnie ten mechanizm odpowiada za spójność i trafność generowanych wypowiedzi.
4. Scoring prawdopodobieństwa: Co może być następne?
Po przeanalizowaniu kontekstu model przypisuje prawdopodobieństwo każdemu możliwemu tokenowi, który mógłby pojawić się jako następny. Prognozy te opierają się na wzorcach wyuczonych z ogromnych zbiorów danych treningowych. Na przykład, po sekwencji „Warszawa jest stolicą”, token „Polski” otrzyma bardzo wysokie prawdopodobieństwo.
Autorzy zwracają uwagę na kluczową kwestię: te prawdopodobieństwa odzwierciedlają statystyczne korelacje w danych, a nie sprawdzone fakty. To właśnie dlatego modele językowe są podatne na tzw. halucynacje – generowanie przekonująco brzmiących, ale fikcyjnych informacji. Świadomość tego ograniczenia jest niezbędna do krytycznej oceny otrzymywanych odpowiedzi.
5. Sampling: Wybór następnego elementu układanki
Ostatnim krokiem jest wybór konkretnego tokenu na podstawie rozkładu prawdopodobieństwa. Na ten etap użytkownik ma realny wpływ przez parametry takie jak temperatura (temperature) i top-p.
Parametr temperatura kontroluje poziom losowości. Niska wartość (np. 0.1) sprawia, że model jest bardzo deterministyczny i niemal zawsze wybiera token o najwyższym prawdopodobieństwie. Wysoka temperatura (np. 0.9) wprowadza więcej chaosu, promując bardziej zaskakujące i kreatywne wybory.
Parametr top-p, zwany też nucleus sampling, działa inaczej. Określa on pulę tokenów, z których model może wybierać, ograniczając ją do tych, których łączne prawdopodobieństwo nie przekracza ustalonego progu (np. 0.9). Pozwala to odfiltrować mało prawdopodobne opcje, zachowując jednocześnie pewną różnorodność.
Proces ten powtarza się w pętli: wybór tokenu, aktualizacja kontekstu, ponowne obliczenie prawdopodobieństw i kolejny wybór. Tak, słowo po słowie, budowana jest cała odpowiedź.
Praktyczne wnioski dla użytkownika AI
Zrozumienie tego procesu dostarcza konkretnych wskazówek, jak lepiej wykorzystywać modele językowe:
- Weryfikuj kluczowe informacje: Pamiętaj, że LLM generują tekst na podstawie wzorców, a nie bazy faktów. W przypadku danych liczbowych, cytatów lub instrukcji bezpieczeństwa zawsze sprawdzaj output w wiarygodnych źródłach.
- Steruj kreatywnością za pomocą temperatury: Ustaw niską temperaturę (0.1-0.3) dla zadań wymagających precyzji, jak generowanie kodu lub odpowiedzi faktograficznych. Wyższą temperaturę (0.7-0.9) zastosuj do burzy mózgów, pisania opowiadań lub tworzenia różnorodnych wariantów tekstu.
- Szanuj limity kontekstu: Ograniczenia tokenów są uwarunkowane mocą obliczeniową. Formułuj prompts zwięźle, usuwaj niepotrzebne słowa i pamiętaj, że długa konwersacja „zjada” dostępny limit, co może prowadzić do utraty wcześniejszego kontekstu.
- Wykorzystaj głębię embeddingów: Model rozumie związki znaczeniowe. Możesz mu ufać w zadaniach polegających na parafrazie, grupowaniu tematycznym czy dostosowywaniu stylu wypowiedzi do podanego kontekstu.
Znajomość etapów od tokenizacji po sampling pozwala świadomie kształtować interakcję z AI. Niezależnie od tego, czy piszesz kreatywny content, analizujesz dane, czy szukasz rozwiązania problemu, to zrozumienie pomaga wydobyć z modelu to, co najlepsze, minimalizując jednocześnie ryzyko błędów. Autorzy testujący te mechanizmy pokazują, że to nie magia, a precyzyjna inżynieria – którą można nauczyć się obsługiwać.

Dlaczego OpenAI zamyka Sora? Koniec wideo AI

AutoDream: jak Claude AI porządkuje pamięć jak ludzki mózg

Langraph Deploy CLI: Łatwe wdrażanie agentów AI z terminala

4 wzorce na automatyzację kodowania w Claude Code

Midjourney 8 Alpha: Szybszy, ale czy lepszy? Spór wśród artystów
OpenAI zamyka dostęp do Sora dla użytkowników
ChatGPT ma nową bibliotekę na twoje pliki. Jak działa?
Nowy interfejs Copilot Notebooks od Microsoft

Claude zdalnie steruje Twoim komputerem. Jak to działa?

Anthropic uruchamia darmową akademię AI z certyfikatami

LangSmith Sandboxes: Bezpieczne środowiska dla agentów AI
