Świat sztucznej inteligencji pędzi do przodu, oferując coraz sprawniejsze narzędzia. Za tą wygodą często idzie jednak mniej widoczna zmiana: rosnący apetyt platform AI na nasze dane osobowe. Najnowsze badanie firmy Surfshark rzuca światło na niepokojący trend – w ciągu zaledwie roku popularne chatboty, w tym ChatGPT, zwiększyły skalę gromadzenia informacji o użytkownikach aż o 70%. To nie są już tylko anonimowe zapytania; systemy coraz częściej sięgają po dane lokalizacyjne, historię przeglądania czy nawet wskaźniki zdrowotne.
Skala zjawiska: jak bardzo rozrosło się zbieranie danych?
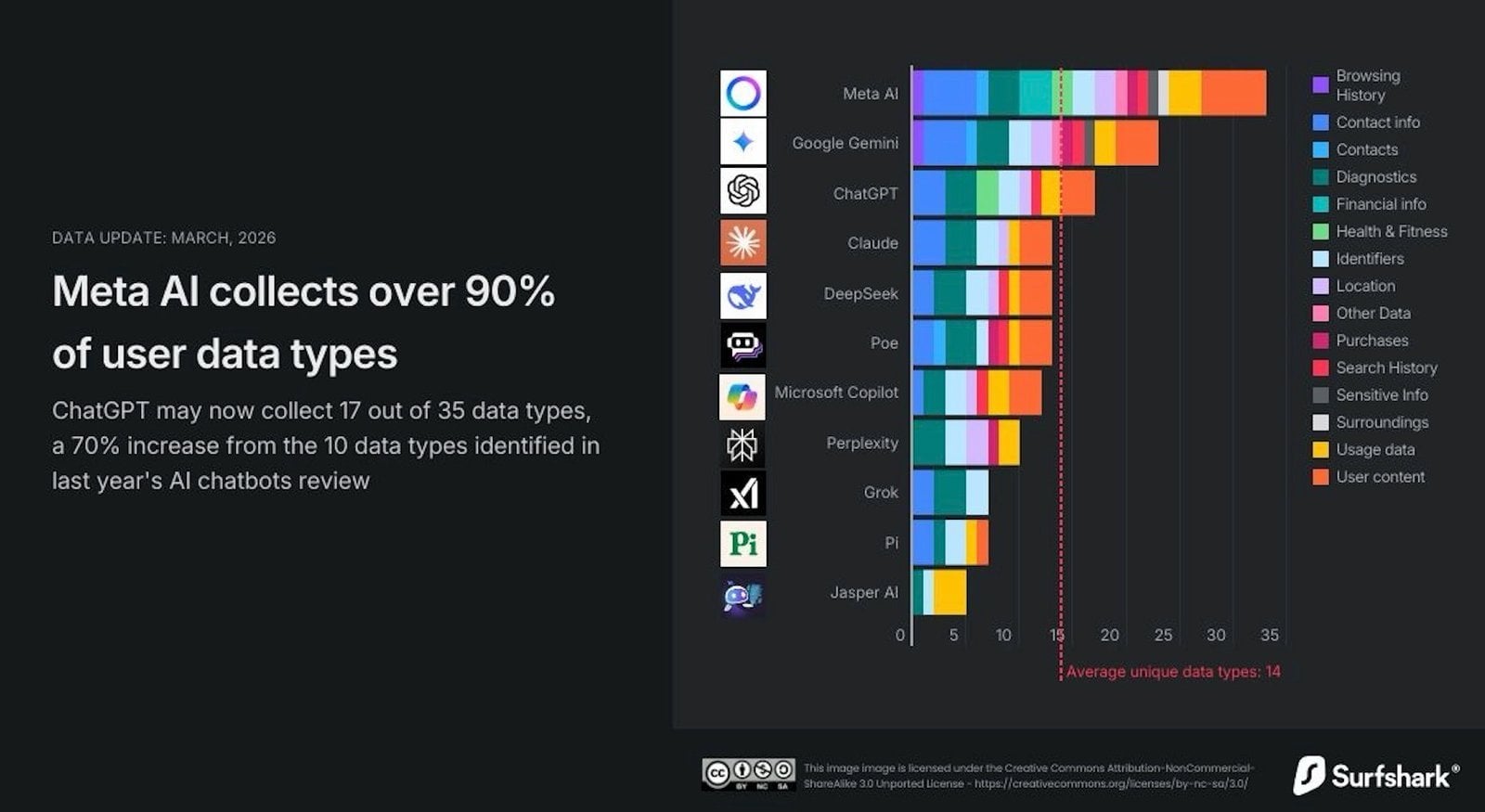
Analiza obejmująca dziesięć popularnych platform ujawnia wyraźną tendencję wzrostową. Podczas gdy rok temu dane dotyczące lokalizacji użytkownika zbierało około 40% badanych chatbotów, dziś robi to już 70% z nich. To tylko wierzchołek góry lodowej. Same praktyki OpenAI są wymownym przykładem: ChatGPT aktualnie pozyskuje 17 różnych rodzajów informacji z potencjalnych 35 badanych kategorii. Na liście tej znajdują się m.in. historia wyszukiwań, dane audio czy informacje związane ze zdrowiem.
Uzasadnienie vs. rzeczywistość
Dostawcy technologii argumentują, że tak szeroki zakres gromadzonych informacji jest niezbędny. Mają służyć polepszaniu funkcjonalności aplikacji, dostarczaniu spersonalizowanych odpowiedzi, udoskonalaniu algorytmów poprzez analitykę oraz – co często pomijane w głównej narracji – optymalizacji reklam targetowanych. Eksperci ds. prywatności wskazują jednak, że granica między niezbędną poprawą usługi a nadmierną inwigilacją staje się coraz bardziej zamazana.
Kto zbiera najwięcej? Ranking „żarłocznych” platform AI
Nie wszystkie narzędzia sztucznej inteligencji podchodzą do kwestii danych w ten sam sposób. Badanie pozwoliło wyłonić prawdziwych liderów, jeśli chodzi o zakres zbieranych informacji. W czołówce znalazły się platformy największych gigantów technologicznych.
Meta AI na czele stawki
Bezkonkurencyjnym liderem okazał się chatbot Meta AI, który gromadzi aż 33 z 35 możliwych typów danych. W jego zasobach mogą znaleźć się nie tylko podstawowe dane kontaktowe, ale także szczegóły finansowe, pełna historia przeglądania internetu oraz inne wrażliwe informacje osobiste. Tak szeroki zakres czyni go najbardziej „żarłocznym” narzędziem w analizowanym zestawieniu.
Pozostali główni gracze
Tuż za liderem plasuje się Google Gemini, zbierający 23 kategorie danych, w tym precyzyjne dane lokalizacyjne. ChatGPT, z wspomnianymi 17 rodzajami informacji, sytuuje się w środku stawki. Nieco mniej, bo po 13 kategorii, zbierają modele Claude od Anthropic oraz chiński DeepSeek. To ostatnie narzędzie budzi jednak szczególne obawy ekspertów z innego powodu.
Poważne wyzwania etyczne i prawne
Ekspansja w zbieraniu danych niesie za sobą konkretne ryzyka i pytania, na które branża musi pilnie odpowiedzieć. Gromadzenie tak wrażliwych informacji jak dane medyczne, dokumenty podatkowe czy szczegóły finansowe otwiera furtkę do potencjalnych nadużyć.
Problem zgodności z regulacjami
Główny zarzut dotyczy braku przejrzystości i zgodności z obowiązującymi przepisami, takimi jak unijne RODO (GDPR). Szczególnym przypadkiem jest DeepSeek, który przechowuje dane użytkowników w Chinach, czyli poza zasięgiem europejskich i amerykańskich regulacji ochrony danych. W praktyce oznacza to, że osoby korzystające z tego narzędzia mają bardzo ograniczone możliwości dochodzenia swoich praw w przypadku wycieku lub nieuprawnionego wykorzystania ich informacji.
Ryzyko komercjalizacji wrażliwych rozmów
Kolejnym palącym problemem jest potencjalne wykorzystanie pozyskanych danych do celów komercyjnych, np. ultra-spersonalizowanych reklam. Wyobraźmy sobie, że system analizując nasze pytania o objawy chorobowe, zaczyna nam później wyświetlać reklamy konkretnych leków lub klinik. Taki scenariusz, choć brzmi jak czarny sen, jest technicznie możliwy przy braku odpowiednich zabezpieczeń i jasnych zasad etycznych.
Brak zgodności z regulacjami, takimi jak RODO, zwiększa ryzyko nadużyć danych i stawia pod znakiem zapytania możliwość pociągnięcia kogokolwiek do odpowiedzialności, szczególnie dla użytkowników z regionów o surowych przepisach ochrony prywatności.
Praktyczne kroki do ochrony swojej prywatności
W obliczu tych trendów użytkownicy nie są całkowicie bezbronni. Istnieje szereg praktycznych działań, które pozwalają znacząco ograniczyć ryzyko i zwiększyć kontrolę nad swoimi danymi podczas korzystania z chatbotów AI.
Przede wszystkim, kluczowa jest świadoma autokontrola. Warto założyć, że każda wpisana w czacie informacja może zostać zapisana i przeanalizowana. Dlatego należy bezwzględnie unikać dzielenia się poufnymi danymi: numerami PESEL czy kont bankowych, szczegółami dokumentacji medycznej, hasłami czy innymi osobistymi identyfikatorami. Drugim filarem jest aktywne zarządzanie ustawieniami. Wiele platform, jak ChatGPT, oferuje opcję wyłączenia historii konwersacji – warto z niej skorzystać, aby ograniczyć długoterminowe przechowywanie dialogów.
Dodatkowe warstwy ochrony mogą zapewnić narzędzia zewnętrzne. Korzystanie z sieci VPN może utrudnić śledzenie lokalizacji i adresu IP. Blokery reklam i skryptów pomagają ograniczyć śledzenie między witrynami. Ostatecznie, choć często pomijane, zapoznanie się z polityką prywatności danej platformy daje świadomość, na co tak naprawdę wyrażamy zgodę. Jeśli dokument jest niejasny lub budzi wątpliwości, to najlepszy sygnał, by rozważyć zmianę narzędzia.
Pilna potrzeba przejrzystości i regulacji
Raport Surfshark wyraźnie pokazuje, że rozwój technologii AI wyprzedza tworzenie ram prawnych i etycznych chroniących użytkownika. Dynamiczny wzrost skali zbierania danych przez chatboty to sygnał alarmowy dla regulatorów na całym świecie. Konieczne jest wypracowanie i egzekwowanie standardów, które zapewnią prawdziwą przejrzystość – użytkownicy powinni wiedzieć, co konkretnie jest zbierane, w jakim celu i na jak długo.
Równocześnie odpowiedzialność spoczywa na barkach twórców tych technologii. To oni muszą projektować swoje systemy z poszanowaniem prywatności już na etapie koncepcji (tzw. privacy by design). Innowacje nie powinny iść w parze z inwazją na dane osobowe. Zaufanie użytkowników jest kapitałem, który bardzo łatwo stracić, a niezwykle trudno odbudować. Przyszłość AI powinna być kształtowana przez równowagę między niesamowitymi możliwościami technologicznymi a fundamentalnym prawem człowieka do prywatności.
Claude Cowork dla początkujących – automatyzacja workflow krok po kroku
ChatGPT audyt rachunków: jak oszczędzić nawet 6000 zł rocznie

4 prompty AI, które potroiły przychód jednoosobowej firmy w 12 miesięcy

GEO w 2026: jak zyskać widoczność w odpowiedziach AI
Claude AI zrobił mi tracker finansowy. Porównanie 4 chatbotów

Vibe coding dla początkujących – zbuduj aplikację w 30 minut

Jak zbudować tarcze ochronne dla agenta AI – 3 metody

Google zapłaci SpaceX 920 mln $ miesięcznie
OpenAI Lockdown Mode – ochrona przed prompt injection

Reklamy ChatGPT w UK – pierwszy europejski rynek otwarty

Boty przejęły internet – ruch AI wyprzedza ludzi
