W dynamicznym świecie sztucznej inteligencji pojawia się kluczowe pytanie: jak obiektywnie zmierzyć, który model jest naprawdę najlepszy? Odpowiedzi na nie szuka LMArena, startup założony przez badaczy z UC Berkeley, który właśnie pozyskał imponujące, wczesne finansowanie w wysokości 150 milionów dolarów. Inwestycja, prowadzona przez fundusz Felicis oraz UC Investments, potroiła wycenę firmy do 1,7 miliarda dolarów w zaledwie siedem miesięcy. To sygnał, że branża dostrzega pilną potrzebę wiarygodnych metod oceny coraz potężniejszych systemów AI.
Dlaczego tradycyjne testy AI już nie wystarczają?
Standardowe benchmarki dla sztucznej inteligencji polegają na zestawie przykładowych pytań i oczekiwanych, poprawnych odpowiedzi. Deweloperzy sprawdzają, jak często ich model udziela trafnych rezultatów, by określić jego wydajność. W praktyce ta metoda ma poważne ograniczenia. Głównym wyzwaniem jest tak zwane skażenie danych (data contamination). Dochodzi do niego, gdy system AI podczas treningu trafił już na pytania testowe lub ich rozwiązania w publicznie dostępnych źródłach. W efekcie model może „wykrzyczeć” test, nie demonstrując prawdziwej zdolności rozumienia i generowania, a jedynie odtwarzając zapamiętane informacje.
Platforma, która stawia na żywe interakcje
LMArena, działająca pod oficjalną nazwą Arena Intelligence Inc., proponuje inne, bardziej dynamiczne podejście. Zamiast statycznych zestawów pytań, jej platforma w chmurze wykorzystuje stale odnawiany zbiór promptów, czyli poleceń dla AI. Są one pozyskiwane od rzeczywistych użytkowników w procesie crowdsourcingu. Platforma oferuje interfejs czatbota, w którym osoba może szukać w sieci, generować kod lub wykonywać inne zadania. Kluczowy jest mechanizm porównawczy: każde polecenie jest wysyłane jednocześnie do dwóch różnych modeli AI, a ich odpowiedzi wyświetlane są obok siebie.
„Nie możemy wdrażać sztucznej inteligencji w odpowiedzialny sposób, nie wiedząc, jak dostarcza ona wartości ludziom” – mówi Anastasios Angelopoulos, współzałożyciel i CEO LMArena. „Aby zmierzyć realną użyteczność AI, musimy oddać ją w ręce prawdziwych użytkowników”.
Jak działa ranking oparty na ludzkich wyborach?
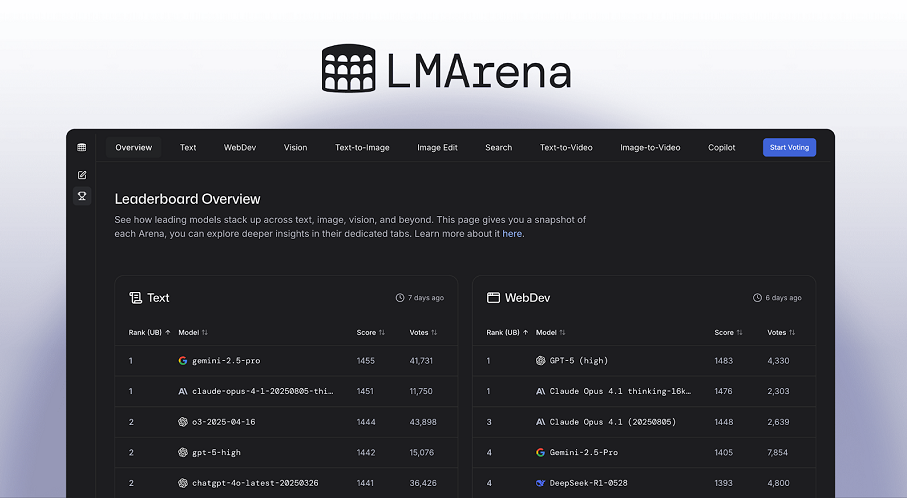
To użytkownik decyduje, która z dwóch równolegle przedstawionych odpowiedzi jest lepsza. Ten wybór stanowi formę feedbacku, który platforma zbiera i analizuje na masową skalę. Na podstawie tysięcy takich codziennych porównań LMArena generuje regularnie aktualizowany ranking najlepiej ocenianych modeli sztucznej inteligencji. Staje się on żywym barometrem jakości.
Aktualny lider i testy wielkich graczy
Według ostatnich danych na szczycie listy znajduje się Gemini 3 Pro, zaawansowany model rozumowania wprowadzony przez Google w listopadzie. Tuż za nim plasuje się jego lżejsza wersja, Gemini 3 Flash, a trzecie miejsce zajmuje Grok 4.1 od xAI. Ranking ten stał się już ważnym narzędziem dla twórców AI. Korzystają z niego, by zbierać informacje zwrotne na temat nowych modeli jeszcze przed ich szeroką premierą. Przykładowo, OpenAI testował swój model GPT-5 na platformie LMArena pod kryptonimem „summit”.
Komercjalizacja i plany na przyszłość
Oprócz publicznego rankingu, startup rozwija komercyjną usługę o nazwie AI Evaluations. Pozwala ona deweloperom na kompleksową ocenę swoich modeli, wykorzystując zgromadzoną bazę feedbacku od użytkowników LMArena. Klienci otrzymują nie tylko końcowe wyniki, ale także dostęp do przykładowych danych, które pozwalają zweryfikować proces oceny. Firma ujawniła, że roczna stopa zużycia (annualized consumption run rate) tej usługi przekroczyła już 30 milionów dolarów.
Na co pójdą pozyskane środki?
Świeżo pozyskane 150 milionów dolarów zostanie przeznaczone na kilka kluczowych obszarów. Przede wszystkim kapitał ma pokryć koszty operacyjne związane z utrzymaniem rosnącej platformy. Część środków zasili inicjatywy badawcze w dziedzinie sztucznej inteligencji, a także pozwoli na zatrudnienie dodatkowych inżynierów. Inwestorami w rundzie Series A, oprócz liderów, były też uznane firmy venture capital, takie jak Andreessen Horowitz, Kleiner Perkins, Lightspeed Venture Partners czy Laude Ventures. Wiele z nich wsparło także wcześniejszą, 100-milionową rundę seed startupu w maju ubiegłego roku.
Rosnąca w zawrotnym tempie wycena LMArena oraz zaangażowanie czołowych funduszy pokazują, że rynek dojrzał do nowych standardów ewaluacji AI. W miarę jak modele stają się bardziej złożone, tradycyjne, zamknięte testy tracą na znaczeniu. Metoda polegająca na ciągłym, masowym porównywaniu przez rzeczywistych użytkowników może stać się nowym, niezależnym punktem odniesienia. To nie tylko kwestia technicznego benchmarku, ale także próba uchwycenia nieuchwytnego: prawdziwej, subiektywnej użyteczności, która ostatecznie decyduje o sukcesie lub porażce technologii w codziennym życiu.


